Étude technique : indicateurs ECM
Généralement, les indicateurs (ECM) attendus sont les suivants :
- Répartition et évolution des documents en nombre et volume
- Comprendre les pics de création de documents
- Répartition des documents en fonction de l’organisation (DGA/Pôle/Département ou Service…)
- Répartition des documents par type de fichiers (extension)
L’indicateur supplémentaire suivant, plus complexe à calculer, est souvent attendu :
Phase1 : répartition et évolution
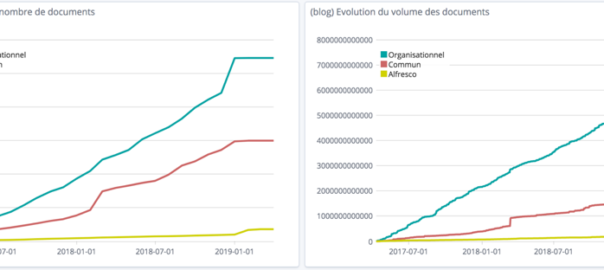
Évolution du nombre total de documents et de leur volume par serveur
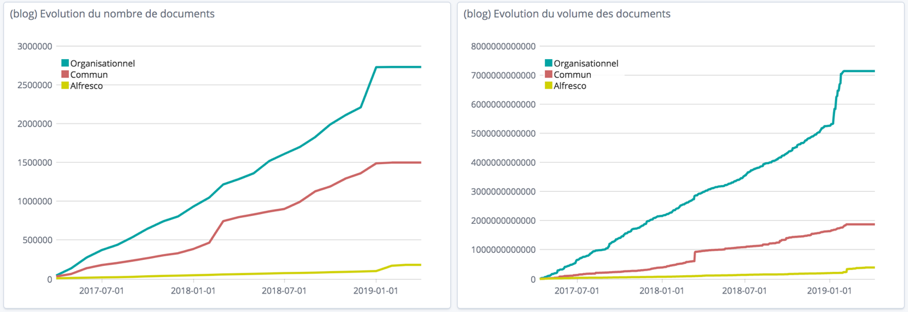
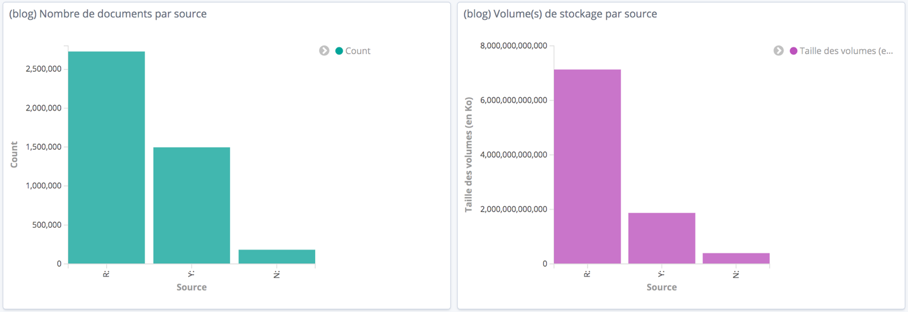
Le stockage est actuellement réalisé sur 3 composants :
- (réseau M) Lecteur : (Organisationnel)
- (réseau N) Lecteur : (Commun)
- (serveur Alfresco) : (Serveur Alfresco)
Le nombre de documents augmente constamment sur chaque composant alors qu’on pourrait s’attendre à voir diminuer ce nombre sur les serveurs réseaux au profit du serveur Alfresco. Au contraire, on constate même que le nombre de documents augmente plus vite sur le lecteur réseau « Organisationnel ».
Alfresco est vraisemblablement utilisé pour répondre à d’autres besoins, notamment des besoins collaboratifs.
Répartition des documents en nombre et en volume entre les différents serveurs
Évolution mensuelle du nombre de création de documents et de leur taille moyenne quelle que soit l’origine des documents
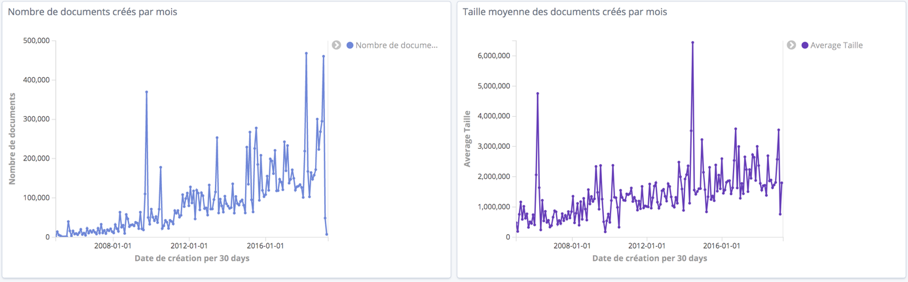
En cliquant sur un point précis, on peut avoir l’explication de sa valeur avec le détail des éléments ayant permis son calcul, comme la liste des documents comptabilités. On s’aperçoit ainsi que les pics de création de documents correspondent à des imports en grand nombre d’éléments de taille importante venant par exemple de la direction technique ou de la communication.
Répartition du nombre de documents par Niv1 (DGA) x Niv2 (Pôle) x Niv3 (Direction…)
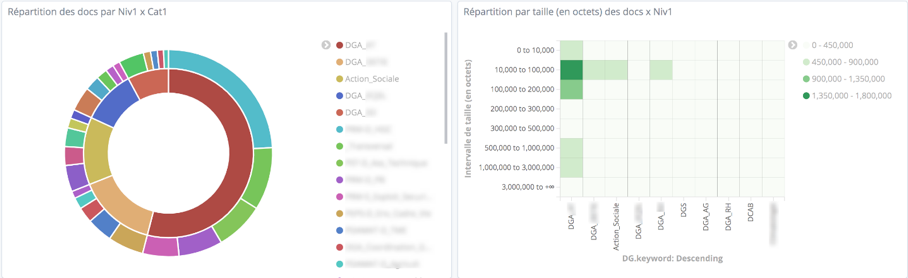
Répartition des documents en fonction du nombre et du volume selon leur extension
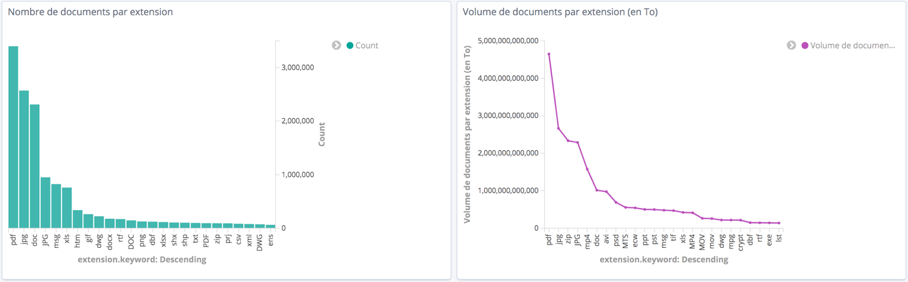
Phase 2 : Recherche des doublons
Plusieurs solutions sont possibles :
- lister les fichiers avec le même nom et regarder par la suite si les documents sont identiques (même taille et même md5). Le hash md5 peut être long à calculer sur des millions de fichiers, cette approche n’est pas toujours envisagée ;
- lister les fichiers avec le même nom et la même taille en une seule passe et vérifier par la suite s’ils ont la même taille.
Cette seconde approche est souvent plus simple et plus rapide à mettre en oeuvre.
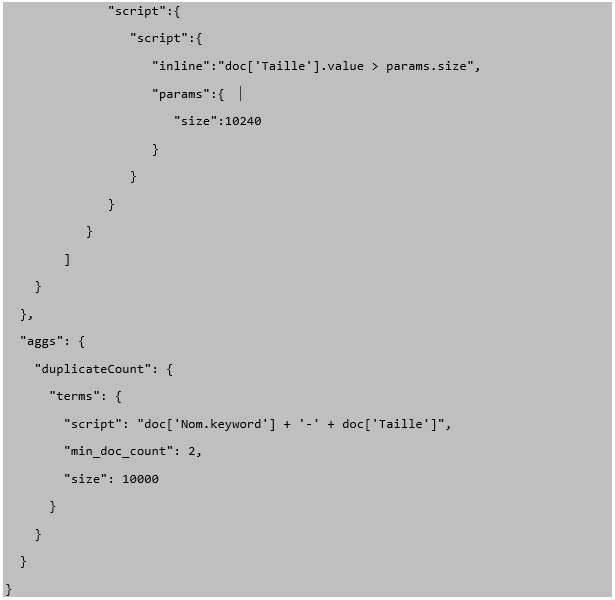
Script
La requête suivante sur ELK permet de récupérer tous les fichiers de plus de 10K dont le nom et la taille sont identiques. Pour garantir qu’il s’agit de doublons, il faudrait utiliser un hash md5 mais à défaut de celui-ci cela permet d’avoir une forte présomption de doublon.

Sur cette base, on peut obtenir un fichier json, qui peut être converti en csv, avec finalement les résultats suivants :
- Nombre de fichiers > 10 Ko étudiés avec le même nom et la même taille : 10 000 fichiers
- Quantité de résultats : 309 173
- Nombre de répétitions : 16 à 2432 (situation.xls)
- Place occupée : 1 835 Mo
- Place optimale : 115 Mo
La taille est multipliée par 15, le nombre de fichiers par 35, ce qui entraîne un gaspillage de ressources, de temps et de maintenance et risque de se traduire par la conservation ‘ad vitam’ de centaines de milliers (pour ne pas dire plusieurs millions) de fichiers redondants…
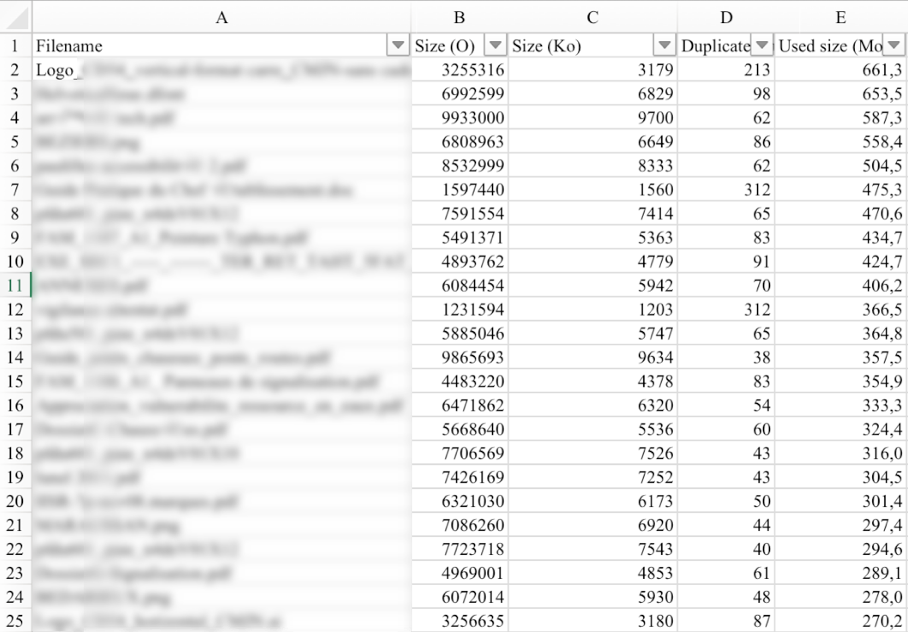
Les 25 plus grandes répétitions quelle que soit la source
Dans notre cas d’utilisation, on ne connaît que les noms de fichiers, mais pas la source. Pour cela, il faudrait faire une requête supplémentaire sur chaque nom afin de savoir comment il se répartit sur chaque racine.
Le nom des fichiers répétés permet de se faire une idée des fichiers redondants.
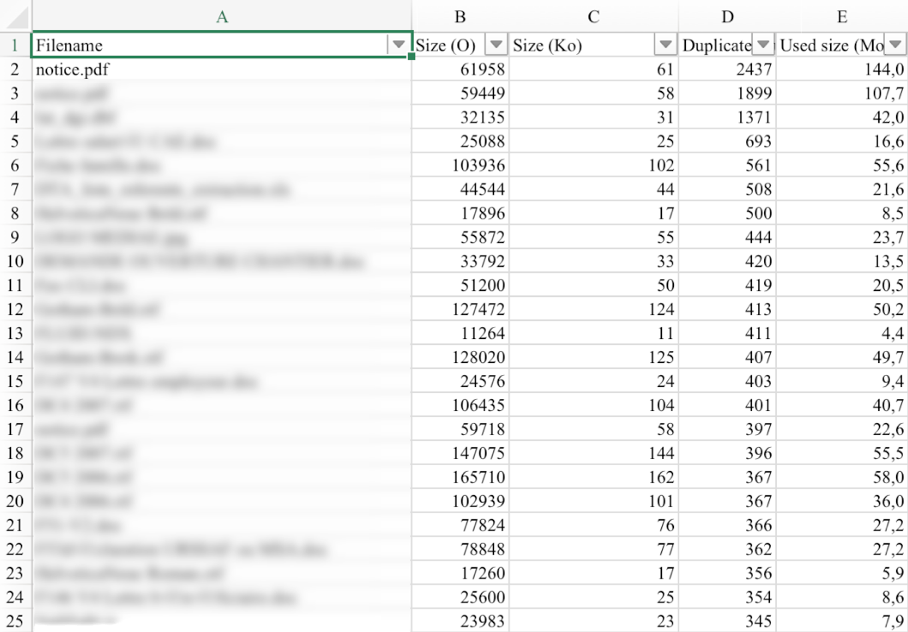
Les 25 plus grands gaspillages
Conclusion (Indicateurs ECM)
L’analyse des doublons est un peu “laborieuse” (données à nettoyer). Un indicateur intéressant serait de calculer la répartition des doublons d’un même fichier sur différentes sources afin de mieux comprendre le mécanisme de propagation et mettre en place des actions pour modifier les comportements.