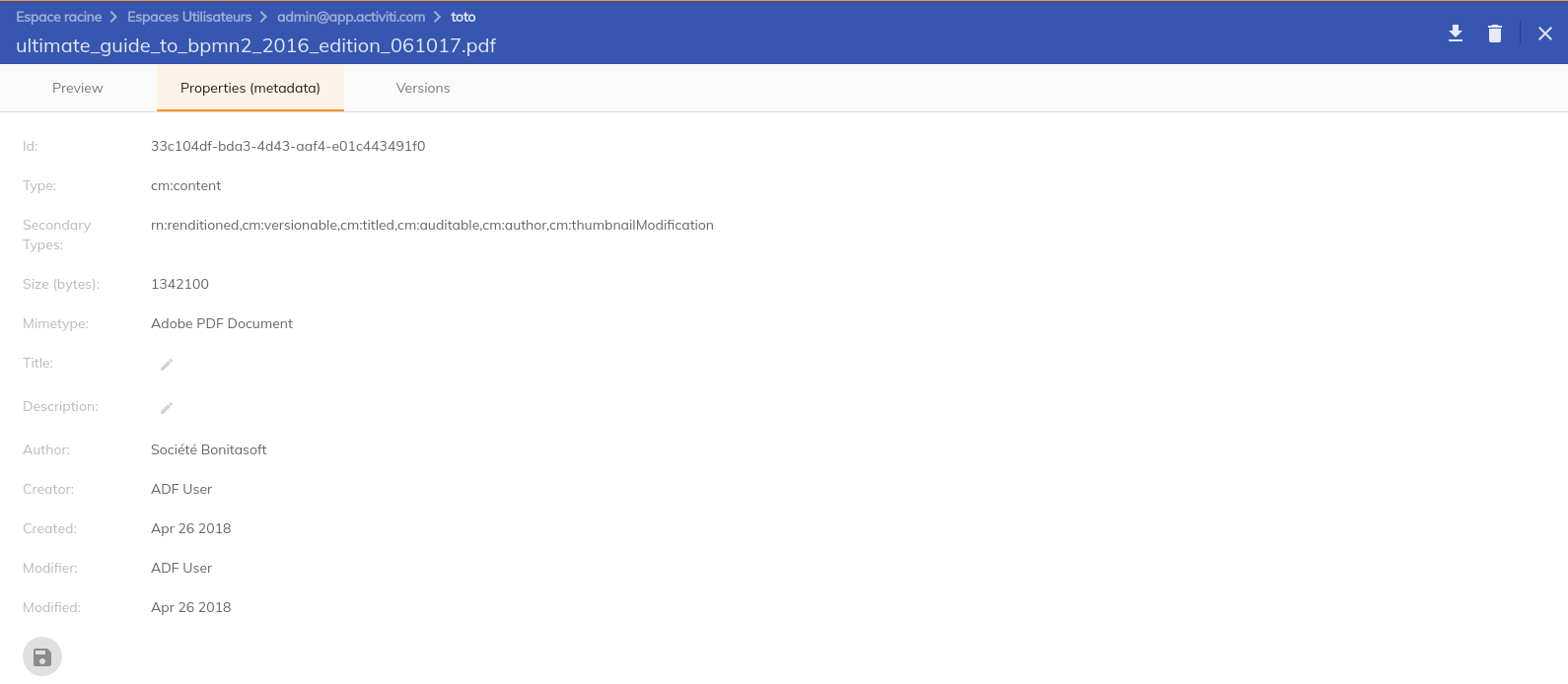
Description
bluereport est un composant qui fournit des indicateurs fonctionnels aux responsables de sites et aux administrateurs de la plateforme, ceci est réalisé dans le but de faciliter le suivi et l’animation des sites collaboratifs, et des indicateurs techniques pour contrôler le fonctionnement des services Alfresco. Selon leur rôle dans l’organisation, les agents ont différents besoins.
- Premièrement, les cadres ont besoin d’informations sur l’utilisation du système, son évolution dans le temps, par typologie et sur tous différents axes possibles (volume de stockage, nombre de documents). Ceci dans le but de justifier d’éventuels investissements qui contribueront à améliorer l’efficacité du système pour répondre aux besoins de l’organisation.
- Deuxièmement, les agents en charge de l’administration fonctionnelle et du support aux utilisateurs de l’application de dématérialisation ont besoin d’informations. Cela leur permet de mieux comprendre les problèmes, leur typologie, leur origine, afin de justifier d’éventuels développements pour faciliter leur tâche et améliorer l’expérience utilisateur.
- Troisièmement, les agents en charge de l’exploitation du système ont besoin d’informations afin de diagnostiquer certains problèmes techniques et de faciliter la communication avec les équipes de TMA.
Ainsi, bluereport vous fournit différents tableaux de bord en fonction de vos droits :
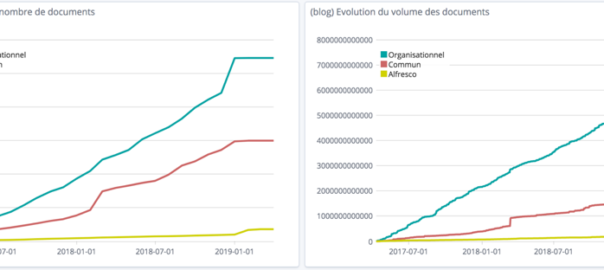
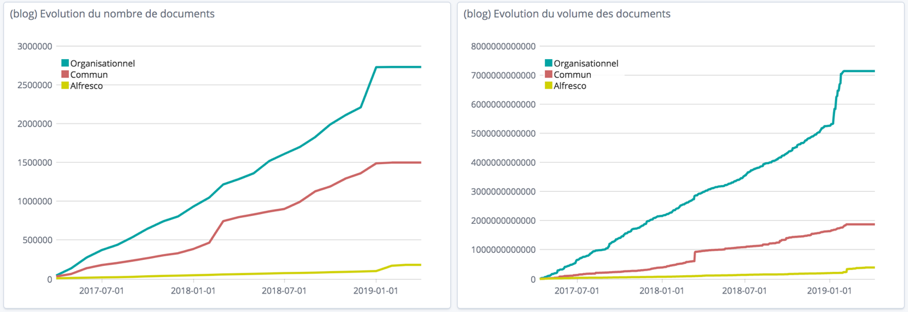
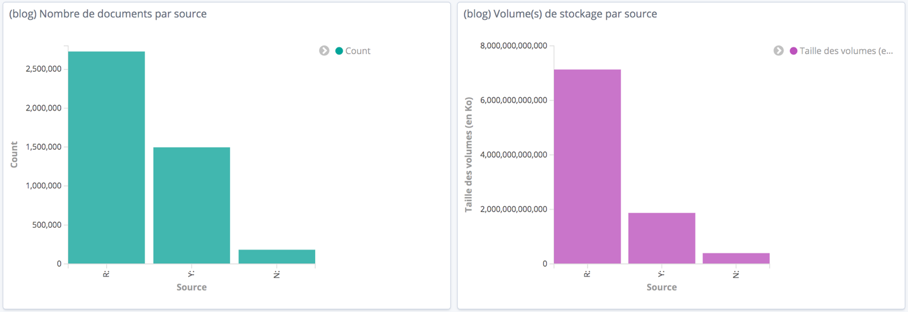
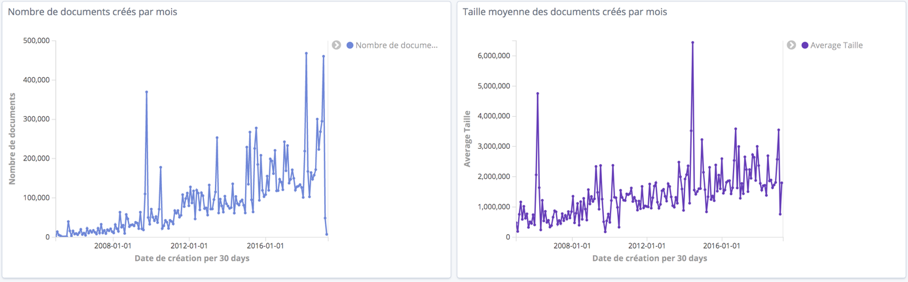
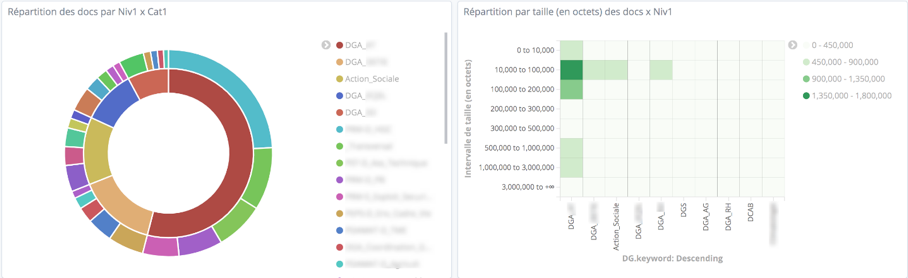
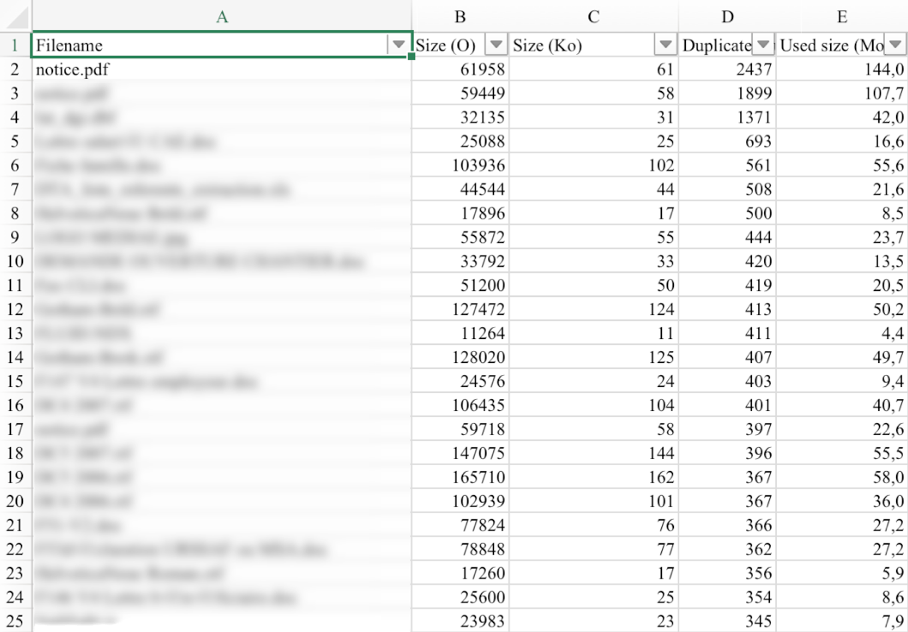
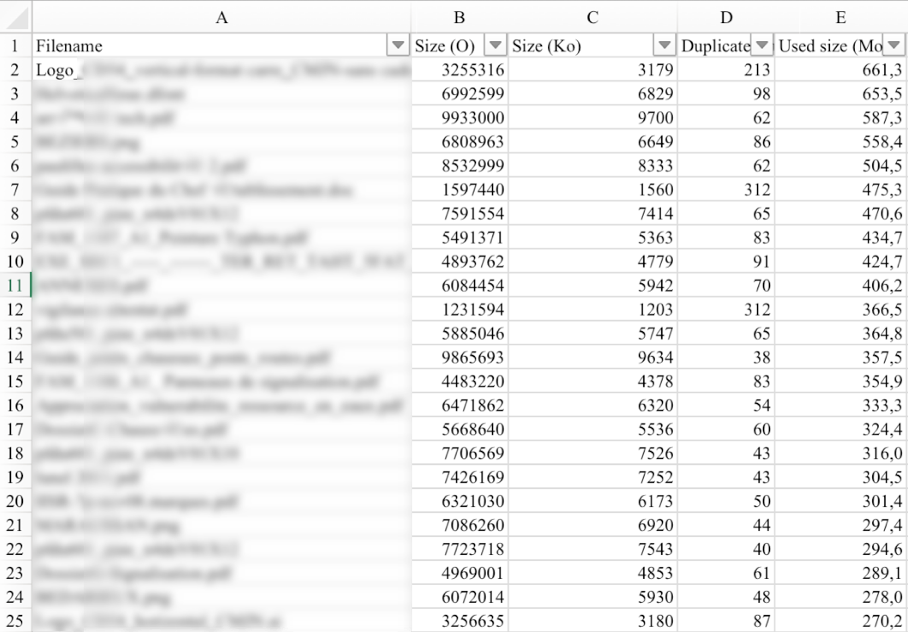
(1) Indicateurs fonctionnels : nombre et volume de stockage des documents métiers (cf figure 1), nombre des documents en cours de dématérialisation – qualifiés et non classés (cf figure 2).
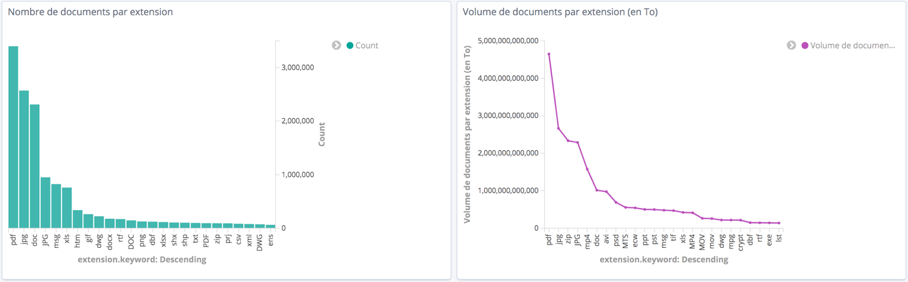
(2) Indicateurs d’administration fonctionnelle : nombre d’erreurs (cf figure 3), d’anomalies.
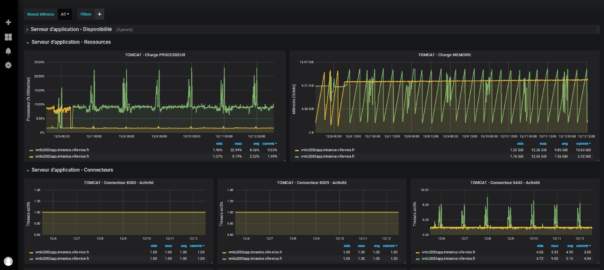
(3) Indicateurs techniques d’exploitation : quantité de ressources utilisées – mémoire, CPU (cf figure 4), logs.
En somme, ces indicateurs peuvent être déclinés par service, dans le temps, afin d’affiner l’analyse et identifier les problèmes, leur origine. En centralisant les logs issus des différents éléments de l’architecture, le diagnostic des problèmes sera donc facilité. Donc ceci contribuera à fournir un service plus efficace.
Indicateurs fonctionnels
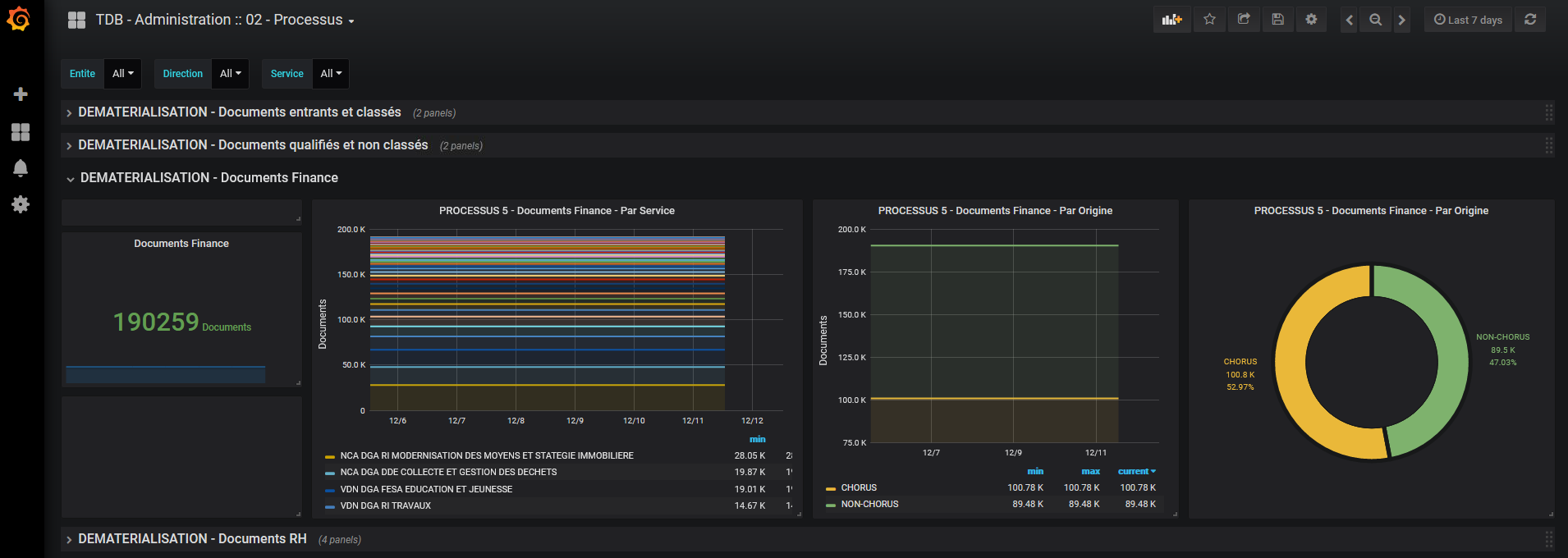
Figure 1 : Activité des documents “finance”
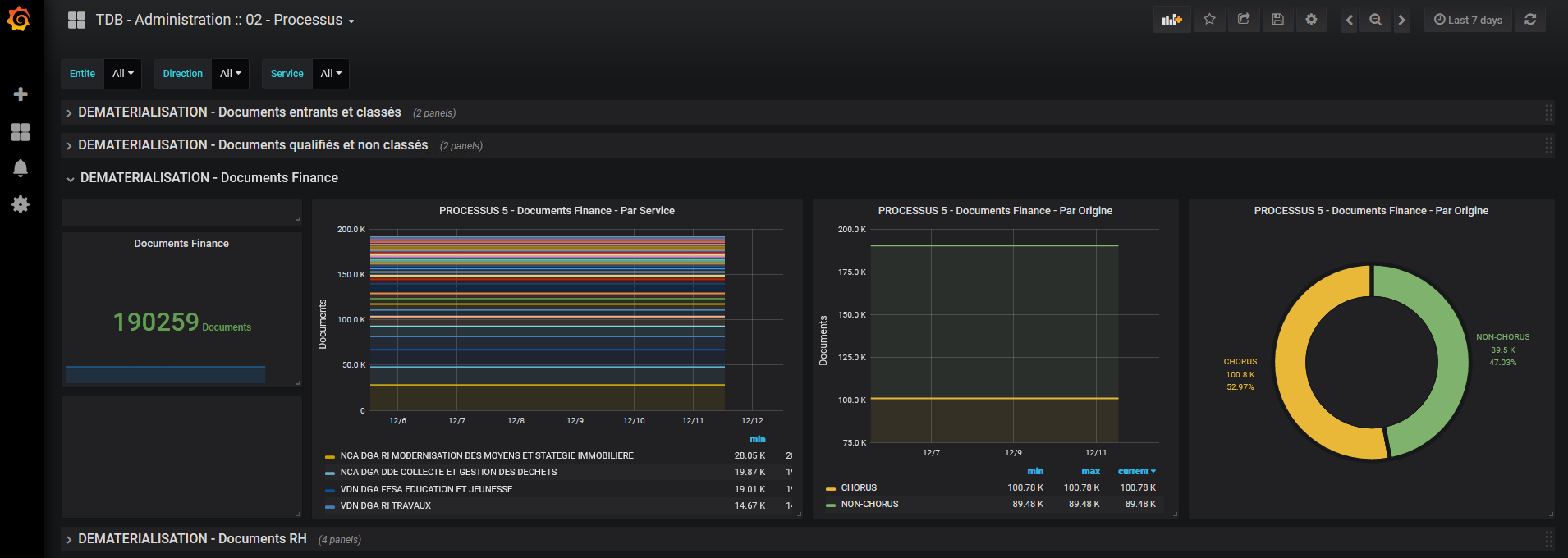
Figure 2 : Nombre de documents en cours de dématérialisation (qualifiés et non classés)
Indicateurs fonctionnels d’administration
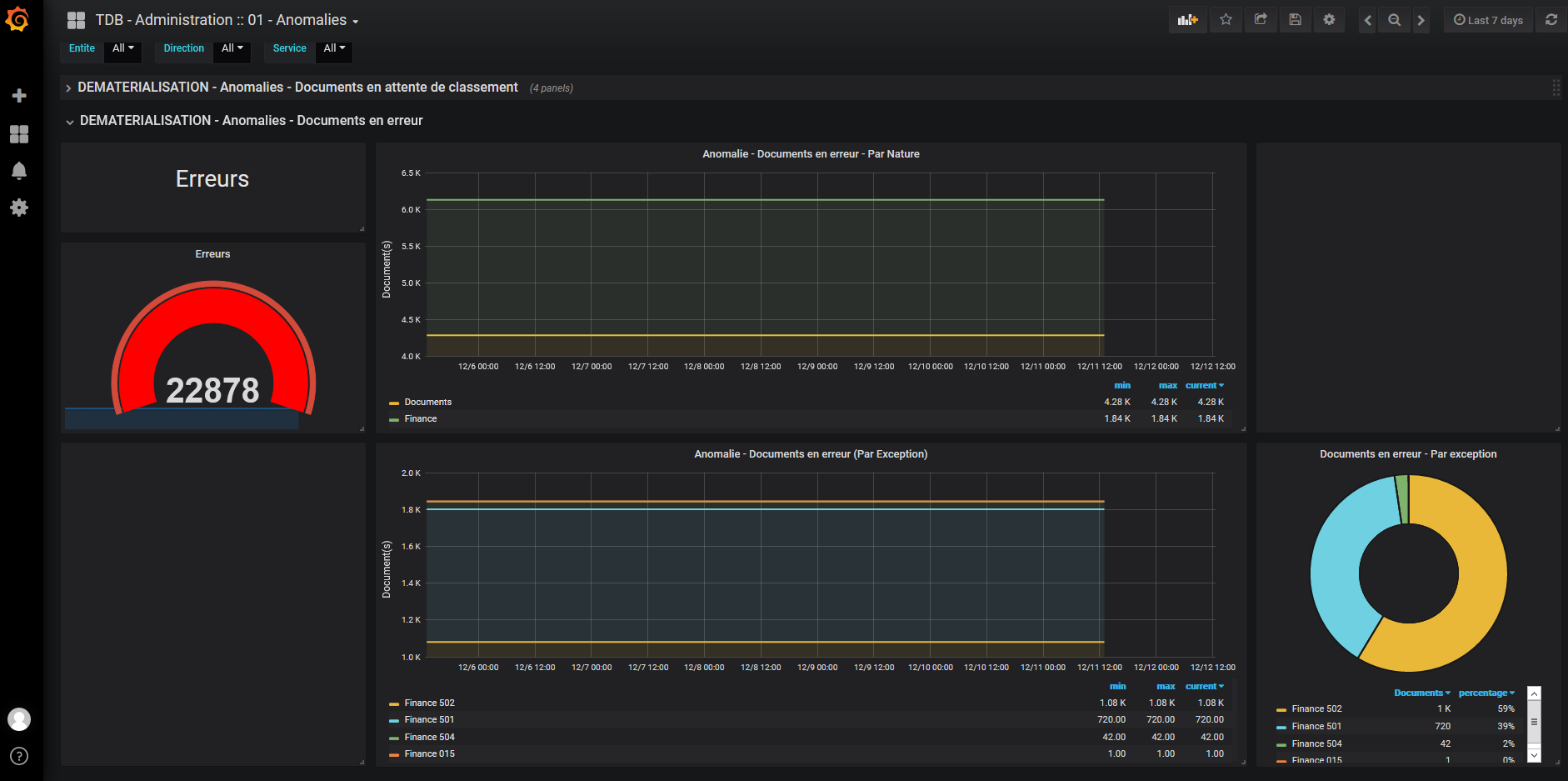
Figure 3 : Documents en erreur
Indicateurs techniques
Le composant bluereport permet aussi de donner des indicateurs techniques, concernant la plateforme Alfresco.
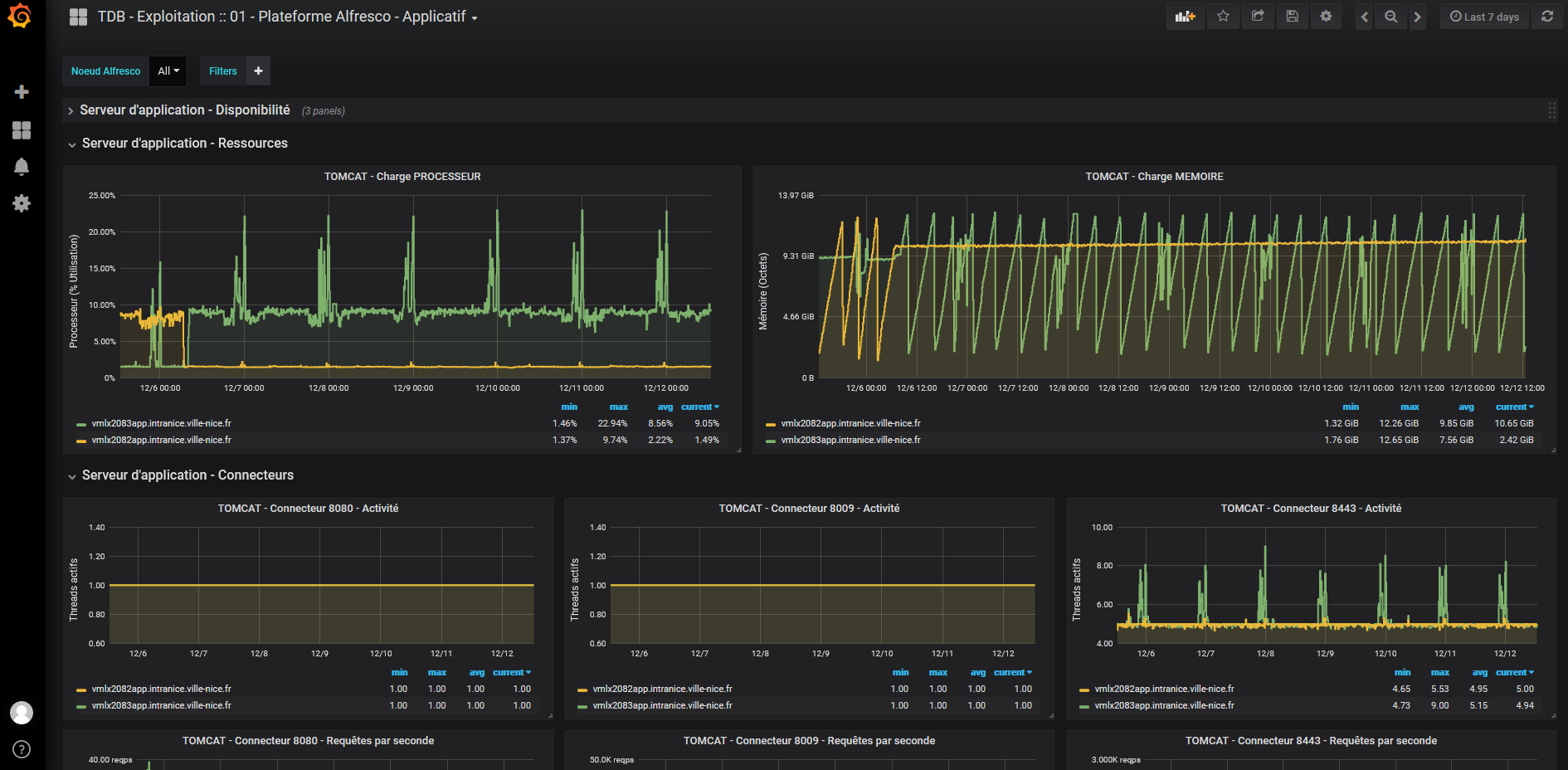
Figure 4 : Ressources du serveur d’application
Fonctionnalités
Finalement, voici la liste des fonctionnalités existantes.
STATISTIQUES FONCTIONNELLES
FONC_1 – NOMBRE DE DOCUMENTS EXISTANTS
STATISTIQUES D’ADMINISTRATION
ANOMALIES
ANO_1 – NOMBRE DE DOCUMENTS EN ATTENTE DE CLASSEMENT
ANO_2 – NOMBRE DE DOCUMENTS EN ERREUR
PROCESSUS
PROCESS_1 – DEMAT – DOCS ENTRANTS
PROCESS_2 – DEMAT – DOCS QUALIFIES
PROCESS_3 – DEMAT – DOCS CLASSES
PROCESS_4 – DEMAT – DOCS NON CLASSES
PROCESS_5 – FINANCE – SUIVI DES FACT.
PROCESS_6 – RH – NOMBRE DE DOCS.
RECHERCHE
RECHERCHE_1 – RECHERCHES
STATISTIQUES D’EXPLOITATION
PLATEFORMES ALFRESCO
EXP_SRV_1 – CHARGE PROCESSEUR.
EXP_SRV_2 – CHARGE MÉMOIRE.
EXP_SRV_3 – CHARGE DISQUE.
EXP_SRV_4 – ESPACE DISQUE DISPONIBLES.
SERVEUR D’APPLICATION
EXP_APP_1 – CHARGE PROCESSEUR.
EXP_APP_2 – CHARGE MÉMOIRE.
EXP_APP_3 – AJP – DISPONIBILITÉS.
EXP_APP_4 – AJP – TEMPS DE TRAITEMENTS.
EXP_APP_5 – TEMPS DE DISPONIBILITÉ.
EXP_APP_6 – SUIVI DES JOURNAUX.
EXP_APP_7 – NB DE SESSIONS OUVERTES.
EXP_APP_8 – DURÉE MOY. DES SESSIONS.
SERVEUR BASE DE DONNÉES
EXP_BDD_1 – CHARGE PROCESSEUR.
EXP_BDD_2 – CHARGE MÉMOIRE.
EXP_BDD_3 – ESPACE DISQUE DISPONIBLE.
Vous souhaitez donc en savoir plus sur notre prestation d’intégration et développement ? Lisez notre article